Henry VIII and The Two Noble Kinsmen
from First Principles
This report presents the full findings of a first-principles computational authorship study of Henry VIII. It expands substantially on the accompanying PDF, explaining every methodological decision in plain prose, comparing results against recent scholarship, and providing the complete chunk-level data. The central finding: the broad traditional Fletcher scene map is too coarse. The play has a strong Shakespearean backbone with a smaller number of locally persistent Fletcherward pockets — narrower and more fragile than scene-level tradition implies.
1. The Problem
Henry VIII — or All Is True, as the play was known in its own time — is one of the longest-running authorship debates in Shakespeare studies. The play was printed in the First Folio of 1623 without attribution to any collaborator. It was accepted as entirely Shakespeare's until 1850, when James Spedding argued from internal verse evidence that substantial portions must be by a different hand. That hand, he proposed, was John Fletcher.
Spedding's argument has proven remarkably durable. It was reinforced by Cyrus Hoy's linguistic-marker work in the early 1960s, extended by Jonathan Hope's sociolinguistic analysis in the 1990s, and forcefully advocated by Brian Vickers in 2002. More recent computational work — especially Petr Plecháč's rolling attribution study published in Digital Scholarship in the Humanities in 2021 — broadly supports collaboration while introducing some refinements to the scene-level map.
Yet the question has also never been fully settled. A determined minority of scholars has maintained Shakespeare's sole authorship. Editors have generally been cautious about exact internal boundaries. And the methods used to argue for collaboration have shifted substantially over time: from verse metrics, to linguistic markers, to function-word profiles, to rolling computational attribution.
This project does not try to settle the full history of the question in one stroke. It does something more focused: it begins from the text itself rather than from a previously published map, it validates every method before interpreting results, and it asks what survives when suspicious scenes are divided into their local dramatic sub-units.
Why this is a hard problem
Four features of Henry VIII make the authorship question genuinely difficult, independent of any particular method:
- No external documentary evidence. There is no contemporary document directly naming Fletcher as co-author. The collaboration hypothesis rests entirely on internal evidence — style, vocabulary, verse patterns, and linguistic habit.
- The play contains multiple dramatic registers. Ceremonial pageantry, legal accusation, comic crowd scenes, intimate prophecy, and political counsel all appear in the same play. Different dramatic registers can themselves generate different stylometric profiles, independent of authorship.
- The First Folio text may have been mediated. Compositorial practice, scribal transcription, and editorial normalization can affect the very features — spelling, contraction, function-word choice — that authorship methods depend on.
- Methods disagree on units of attribution. Some scholars work at the scene level. Others work at the rolling-window level. Others work scene-by-scene. The scale at which you measure can determine what you find.
2. The History of Scholarship
Understanding the current project requires understanding what the existing scholarship has and has not established. The following is an expanded review of the major positions, with particular attention to their methodologies and their limitations.
The historical starting point. Spedding argued from verse endings — particularly feminine endings — that large portions of the play bore a different stylistic character from Shakespeare's late verse. His proposed Fletcher territory included scenes 1.3, 1.4, 2.1, 2.2, 3.1, 4.1, 4.2, 5.3, and 5.4. This became the "canonical" map that most subsequent scholars have either defended or modified. Importantly, Spedding's method was already lineation-sensitive: he noticed that verse structure (not just vocabulary) differed. The current project's verse-and-rhyme analysis is a direct methodological descendant of this instinct.
Hoy's contribution was to shift the evidence from verse metrics to linguistic markers. He documented Fletcher's distinctive preferences — ye for you, 'em for them, has for hath, does for doth — across a large corpus of Fletcher's secure work. He found that these markers clustered in the Spedding-attributed scenes of Henry VIII, broadly confirming the scene map. The current project tests these markers carefully: several validate strongly on the secure reference corpus, but some (ye especially) are complicated by transmission and dramatic mode.
Hope introduced a sociolinguistic approach, focusing on second-person pronoun usage (the T/V distinction: thou/thee vs. you/your) as a marker of social register and authorial habit. His results supported collaboration in a general sense, though with important caveats about the relationship between sociolinguistic habit and dramatic mode. The current project tests the T/V layer independently; it validates at a moderate level (0.727 overall accuracy) but is not strong enough to adjudicate the full map alone.
Vickers's monograph offered the most sustained advocacy for the collaboration hypothesis across multiple plays, including Henry VIII. He treated several scenes as securely Fletcherian and challenged critics who resisted the attribution. The current project is more cautious about the same scenes: 5.2 now looks largely Shakespearean under chunk-level analysis, and 3.1 appears unresolved rather than decisively Fletcherian.
The most important recent computational study. Plecháč combined most-frequent-word analysis with most-frequent-rhythmic-pattern analysis, using rolling attribution to assign authorship probabilities across the play without being locked to scene boundaries. His results broadly support Spedding while adding modifications that partially align with earlier Merriam-style analyses. He found that authorship shifts do not always respect scene boundaries — a key finding that this project's manual chunking approach also supports. However, his rolling trace is considerably more Fletcherward than the current project's local reproduction with a validated reference corpus.
Craig and Kinney's function-word tests of six Henry VIII scenes found that Fletcher wrote 3.1 and 5.2, while Shakespeare wrote the other four tested scenes. Their results partially diverge from the full Spedding map, and subsequent scholars have criticized their Zeta methodology. The current project independently recovers a conservative reading: 3.1 appears mixed rather than decisively Fletcherian, and 5.2 appears largely Shakespearean in three of four sub-chunks.
Sharpe edited Henry VIII for The New Oxford Shakespeare and has continued to work on collaborative writing methodology. His 2023 Oxford book frames collaborative authorship in terms of theatre history, book history, and attribution evidence together. The NOS edition takes a cautious position on exact boundaries while affirming collaboration. This editorial caution is strongly aligned with the main finding of the present project.
Both the Folger and Cambridge editorial traditions treat collaboration as highly plausible but refrain from drawing firm scene-by-scene boundaries. The Folger appendix notes that the collaboration hypothesis rests on internal evidence without documentary confirmation. This position — collaboration is likely, exact boundaries remain unstettled — is precisely where the present project also lands.
Recent Literature (2020–2026)
Beyond the core texts above, the following recent scholarship is relevant to the present project:
- Plecháč (2021, DSH): The published version of the arXiv preprint (1911.05652). Full citation: "Relative contributions of Shakespeare and Fletcher in Henry VIII: An analysis based on most frequent words and most frequent rhythmic patterns." Digital Scholarship in the Humanities 36.2 (2021): 430–438. This is the most directly comparable computational study. The current project's rolling attribution result is considerably more conservative than Plecháč's — the key difference being the reference corpus and feature-family choice.
- Plecháč replication data (GitHub: versotym/henry8): Plecháč made all data and code publicly available. The present project did not use his code, but the availability allows direct methodological comparison. His method combines vocabulary frequency and verse rhythm; the current project uses character trigrams, function words, and linguistic markers, then adds CWFP as a content-word layer.
- Sharpe (2023, Shakespeare & Collaborative Writing, OUP): A systematic methodological and historical account of Shakespeare's collaborative practices. Includes Henry VIII and The Two Noble Kinsmen as central cases. Key contribution: framing collaboration attribution as a problem of convergence across evidence types rather than any single test — exactly the multi-method approach this project uses.
- Stanford Global Shakespeare Encyclopedia entry on Henry VIII: A useful recent summary of the scholarly consensus, noting that while most scholars now accept collaboration, "scholars using different methods have attempted to discriminate between Shakespeare's and Fletcher's parts without arriving at consensus."
- Analytics India Magazine (2019–2020) / TechXplore coverage of ML approaches: Popular-science coverage of machine-learning attribution claiming Fletcher wrote roughly half the play. These reports often overstate the certainty of rolling attribution results. The present project's validation-first design is partly a response to overconfident ML claims in this space.
- 2021 Stylometric reanalysis (Craig/Kinney critique): Subsequent scholarship has identified methodological problems with the Zeta test as implemented in the 2009 Craig/Kinney volume. This critique is relevant because it shows how sensitive attribution conclusions can be to feature selection and distance metric — a core concern of the present validation framework.
3. Data, Texts, and the Reference Corpus
The database
All analysis rests on a local SQLite database of 527 early modern English plays. The database stores spoken-token sequences, lemmas (via MorphAdorner), speaker information, act/scene structure, and bibliographic metadata. Lemmatization allows comparison of lexical habits independently of surface spelling variation, which matters significantly for a play like Henry VIII where compositor practice may have standardized or altered original spelling.
The target play is Henry VIII (database play ID 502, 36th play in the First Folio subset). A diplomatic Folger transcription was separately consulted for the original-spelling investigation.
The secure reference corpus
Author-comparison analysis uses a deliberately narrow set of secure reference plays. These are plays whose single authorship is not seriously disputed and which provide enough text for reliable window-level comparison. The corpus is not claimed to represent the entirety of either author's output — it represents plays secure enough to use as a calibration standard.
| Author | Play | Tokens |
|---|---|---|
| Fletcher | Bonduca | 20,226 |
| Fletcher | The Faithful Shepherdess | 19,962 |
| Fletcher | The Loyal Subject | 25,579 |
| Fletcher | The Mad Lover | 18,378 |
| Fletcher | The Woman's Prize | 22,858 |
| Fletcher | Valentinian | 24,552 |
| Shakespeare | Antony and Cleopatra | 23,855 |
| Shakespeare | As You Like It | 21,442 |
| Shakespeare | Coriolanus | 26,675 |
| Shakespeare | Hamlet | 29,897 |
| Shakespeare | Henry IV, Part 1 | 24,091 |
| Shakespeare | Henry IV, Part 2 | 25,899 |
| Shakespeare | Henry V | 25,702 |
| Shakespeare | Julius Caesar | 19,131 |
| Shakespeare | King Lear | 25,376 |
| Shakespeare | Macbeth | 16,547 |
| Shakespeare | Measure for Measure | 21,346 |
| Shakespeare | Othello | 25,967 |
| Shakespeare | Richard II | 21,864 |
| Shakespeare | The Tempest | 16,159 |
| Shakespeare | Twelfth Night | 19,548 |
| Shakespeare | Much Ado About Nothing | 21,442 |
The corpus has 16 Shakespeare plays and 6 Fletcher plays. The asymmetry matters: the method will be more comfortable recognizing Shakespeare than Fletcher, and this is confirmed in validation. All conclusions are read against this known asymmetry.
Six governing assumptions
- No previously published Henry VIII section map functions as the answer key.
- Large scenes are not presumed homogeneous. If a scene changes local dramatic function, it may need manual subdivision.
- No method is interpreted before being validated on secure single-author material.
- No single feature family decides the case alone.
- TNK can be used as a definitely mixed Shakespeare–Fletcher play, but not as a secure internal partition map.
- Any chunk that weakens substantially under finer subdivision is treated cautiously, even if it looked persuasive at coarser scale.
4. How Henry VIII Was Manually Chunked
Why scene level was not enough
The project did not begin with the 46-chunk map. It began with scene-level exploration. That first pass immediately revealed a problem: many of Henry VIII's scenes are too long and too internally varied to be treated as single authorial units. A single scene in this play may contain a ceremonial opening, a legal accusation, a private emotional reaction, a packet exchange, and a formal conclusion — five dramatically distinct phases within one scene boundary. Attributing that kind of scene to one author is not just potentially wrong; it is not even a well-formed question.
The methodological response was manual chunking: inserting boundaries only where the dramatic action itself makes a local break intelligible, in the way a literary critic would notice a change even without any stylometric agenda.
Principles of chunking
A new chunk boundary was drawn when one or more of the following occurred:
- A speaker bloc changed (e.g., from public noble exchange to private royal reflection)
- The dramatic function changed (e.g., from ceremonial prelude to legal accusation)
- The local rhetorical mode changed (e.g., from banter to proclamation, or from report to prophecy)
- A scene contained an embedded unit that a literary critic would obviously discuss separately — even without any stylometric question
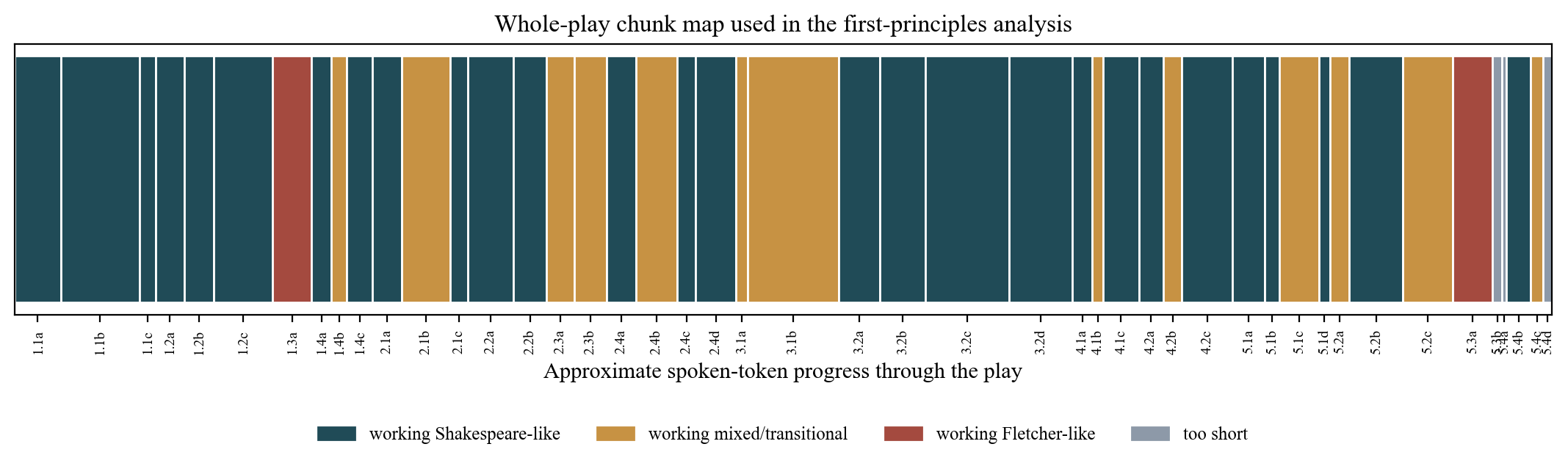
This means the chunk is best understood as a local dramatic unit, not a mechanical token slice. The result was a 46-chunk map across the play's 16 scenes.
Representative chunking examples
| Chunk | Scene | Tokens | Label | Boundary rationale |
|---|---|---|---|---|
1.3a | 1.3 | 575 | Court satire and French fashions | Compact comic-expository scene; kept whole because internal mode stays stable |
3.2a | 3.2 | 607 | Noble coalition and anti-Wolsey exposure | Opening noble conference through Wolsey-Cromwell encounter before private alarm |
3.2b | 3.2 | 679 | Packet exchange and Wolsey's inward alarm | Private alarm and preparation for downfall — distinct from the public confrontation |
3.2c | 3.2 | 123 | Wolsey confronted and stripped | Brief formal article-recital block; highly compressed public humiliation |
3.2d | 3.2 | 935 | Wolsey after the fall | Reflective post-fall aftermath — a dramatically distinct emotional register |
5.4a | 5.4 | 67 | Procession naming and opening blessing | Ceremonial prelude before prophecy; mode shifts sharply from 5.3 |
5.4b | 5.4 | 359 | Cranmer's first prophecy movement | First prophetic arc; internally stable |
5.4c | 5.4 | 182 | Final prophecy and king's answer | Second arc plus royal response; distinct closure movement |
5.4d | 5.4 | 123 | Epilogue | Non-dramatic; separate unit for all analyses |
5. How The Two Noble Kinsmen Was (and Was Not) Used
Earlier drafts of this project were tempted to use The Two Noble Kinsmen (TNK) as a validation case: if a method can recover the familiar internal Shakespeare/Fletcher partition of TNK, then it can be trusted on Henry VIII. This is a tempting shortcut, but it is methodologically circular.
The standard TNK partition (Acts 1, 2, and 5 mostly Shakespeare; Acts 3 and 4 mostly Fletcher) is itself disputed and internally derived. Using it as a validation target means assuming precisely what you are supposed to test. If your method recovers the disputed TNK map, all you have shown is that your method agrees with a prior disputed conclusion — not that either is correct.
This is a narrower use of TNK, but a cleaner one. Under this rule, TNK is useful for the following question: Do Henry VIII and TNK both show mixed internal texture clearly above the single-author baseline? That question can be answered without assuming we know which TNK scenes belong to which author.
6. The Methods, Explained
Method 1: The Refined Stack
The main local attribution method is the "refined stack," combining three feature families. Each Henry VIII chunk is represented in three different ways, and compared against rolling windows of the same length drawn from secure Shakespeare and Fletcher reference plays.
Character trigrams (char): overlapping three-character sequences (e.g., hon, ono, nou from honour). These capture recurrent spelling shapes and some lexical habits without becoming a simple bag of full words. They are particularly useful because they are somewhat insensitive to morphological inflection.
Function-word profile (fw): high-frequency words like and, of, with, for. In authorship work, function words are prized because they are less topic-dependent than content words — a playwright uses the and that habitually, regardless of whether the scene is about love or politics.
Marker profile (marker): a small targeted set of authorship markers with a known prior in Shakespeare/Fletcher attribution — especially pronoun preferences, auxiliary verb choices, and contraction habits (see Method 4 below for detail).
For each feature family, the chunk is compared to reference windows using cosine distance. The best-matching windows on each side are identified. The method then asks: on average, is this chunk nearer to Shakespeare windows or Fletcher windows? If two of three feature families agree on one author, that is the chunk's reading. If they split or the margin is small, the chunk is Mixed.
Method 2: Rolling Attribution
The rolling-attribution pass asks the same authorship question continuously rather than chunk-by-chunk. A fixed-size window (400 or 700 tokens) is moved through the entire play one step at a time. Each window is compared to the secure reference corpus. The result is a continuous Fletcher-proxy trace — a number between 0 and 1 at each position, where higher values indicate closer proximity to the Fletcher reference plays.
This method is the direct local equivalent of Plecháč's rolling attribution. The key difference is the feature stack (trigrams + markers + function words here, versus most-frequent words + most-frequent rhythmic types in Plecháč) and the reference corpus (16 Shakespeare / 6 Fletcher here vs. a different selection in Plecháč).
The rolling method has two advantages over chunk-based analysis: it does not depend on chunk boundary placement, and it can reveal whether apparent Fletcher pressure forms a genuine continuous block or a brief local spike.
Method 3: Verse and Rhyme
The verse-and-rhyme layer reconstructs line-by-line structure from the token sequence and measures several lineation-sensitive features: feminine-ending tendencies, strong end-stopping, shared lines between speakers, and adjacent rhyme density. This layer matters because Spedding's original argument was already lineation-sensitive, and because several scholars (including Plecháč) have found verse patterns diagnostic.
However, in this project's validation, verse features perform only moderately on the secure reference corpus. Feminine endings achieve about 0.727 accuracy for the Shakespeare/Fletcher distinction. Shared-line and end-stop claims are weaker still. The verse layer is therefore used as a secondary check rather than a primary decision criterion.
Method 4: Classic Marker Audit
Rather than simply assuming that the traditional Fletcher markers work, the project tested them against the secure corpus. The question was: which traditional markers actually separate secure Shakespeare plays from secure Fletcher plays in the local reference data?
| Marker | Favors | Accuracy | Strength | Usable? |
|---|---|---|---|---|
| feminine ending rate | Fletcher | 0.727 | moderate | Yes (secondary) |
| ye frequency | Fletcher | 0.909 | strong | Cautiously (transmission-sensitive) |
| 'em rather than them | Fletcher | 0.955 | strong | Yes |
| has rather than hath | Fletcher | 0.955 | strong | Yes |
| does rather than doth | Fletcher | 0.773 | moderate | Yes |
| colloquial contraction density | Fletcher | 0.909 | strong | Yes |
The strongest markers are 'em/them and has/hath, each reaching 0.955 accuracy. The ye marker is strong in principle but complicated by its sensitivity to database normalization — some lemmatization pipelines collapse ye and you, which would suppress the signal. Results using ye are read with extra caution.
Crucially, even strong markers behave unevenly across Henry VIII: they are often local within a scene rather than scene-wide. This is one of the most important empirical results in the entire project — it undermines the traditional assumption that a scene with several Fletcher marker hits is a uniformly Fletcherian scene.
Method 5: Original-Spelling Check
Because spelling arguments recur in the Henry VIII tradition (Hoy's work relied partly on ye and 'em in original spelling), the project returned to a diplomatic Folger transcription of the play. This layer was handled with caution. Ordinary Folio spellings — heere, beleeue, honour — are as likely to reflect compositor practice as authorial habit. More local colloquial forms — ye, 'em, ha's — are more informative but still potentially affected by scribe or compositor.
The main value of this layer is negative: spelling evidence can intensify a pre-existing suspicion, but it does not by itself settle a chunk.
Method 6: Content-Word Frequency Profile (CWFP)
The CWFP method asks a fundamentally different question from the refined stack. It ignores function words and linguistic markers entirely, and compares texts only through recurring content lemmas — words like honour, grace, blood, power, lord, love. The vocabulary is built from ~2,567 content lemmas that appear in at least 50% of reference plays.
CWFP is useful because it provides an independent signal. If a chunk shows Fletcherward pressure in both the refined stack and CWFP, that cross-method convergence is stronger evidence than either alone. CWFP is more vulnerable to subject matter (a politically intense scene will use different content words than a comic one), but it is less vulnerable to the marker-transmission problems that affect function-word approaches.
Method 7: Genre and Mode Contamination Test
The most important methodological question in the entire project is this: could the Fletcherward pressure in suspect Henry VIII chunks simply reflect their dramatic mode rather than their authorship? Court satire might look Fletcherward. Comic crowd scenes might look Fletcherward. Processional narration might look Fletcherward — regardless of who wrote the passage.
The contamination test directly addresses this objection. For each surviving pressure chunk, the project found exact-length windows from secure Shakespeare plays that matched the Henry VIII chunk as closely as possible in dramatic geometry: same approximate speaker count, same turn structure, same concentration of speech among a small number of speakers. These matched Shakespeare windows were then put through the refined stack and CWFP.
If the matched Shakespeare controls also drift Fletcherward, the contamination explanation is supported and the Henry VIII pressure is inconclusive. If the Henry VIII chunks are consistently more Fletcherward than their matched Shakespeare controls, the contamination defense weakens.
7. Validation Before Interpretation
The asymmetry in method performance is the most important single fact about the project's evidentiary standard. It must be understood before any Henry VIII result is interpreted.
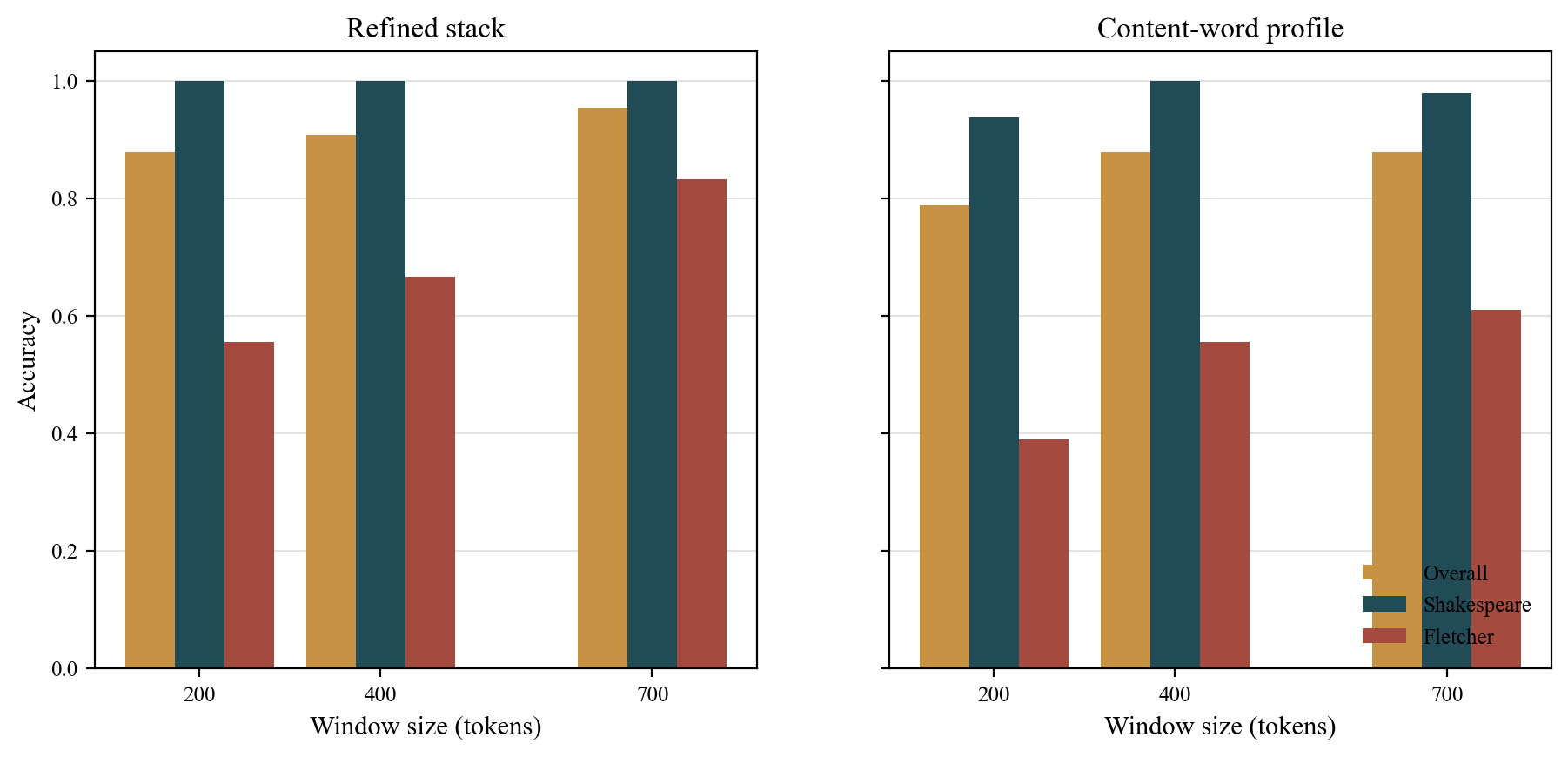
Refined stack validation
Leave-one-play-out validation on the secure corpus gives the following results:
| Window size | Overall accuracy | Shakespeare recovery | Fletcher recovery |
|---|---|---|---|
| 200 tokens | 0.879 | 1.000 | 0.556 |
| 400 tokens | 0.909 | 1.000 | 0.667 |
| 700 tokens | 0.955 | 1.000 | 0.833 |
CWFP validation
| Window size | Overall accuracy | Shakespeare recovery | Fletcher recovery |
|---|---|---|---|
| 200 tokens | 0.788 | 0.938 | 0.389 |
| 400 tokens | 0.879 | 1.000 | 0.556 |
| 700 tokens | 0.879 | 0.979 | 0.611 |
8. The Main Henry VIII Findings
The first-principles analysis produces a result that is neither the broad traditional Fletcher map nor an all-Shakespeare reading. The play has a genuine Shakespearean backbone — visible across multiple methods and across the manual chunking, the rolling attribution trace, and the content-word profile. But a handful of locally persistent Fletcherward pockets survive the full battery of tests.
The Shakespearean backbone
The Wolsey material — the political rise and fall across Acts 1–3 — remains consistently and strongly Shakespearean across the refined stack, rolling attribution, and content-word profile. Scenes like 1.1, 1.2, 2.4, and the entire 3.2 complex (Wolsey's fall and its aftermath) are among the most securely Shakespearean regions in any attribution analysis.
The legal-ceremonial scenes — particularly the trial of Katherine in 2.4 and the Cranmer vindication in Act 5 — are also strongly Shakespearean. The play's political-historical architecture appears to be Shakespeare's in its most fundamental design.
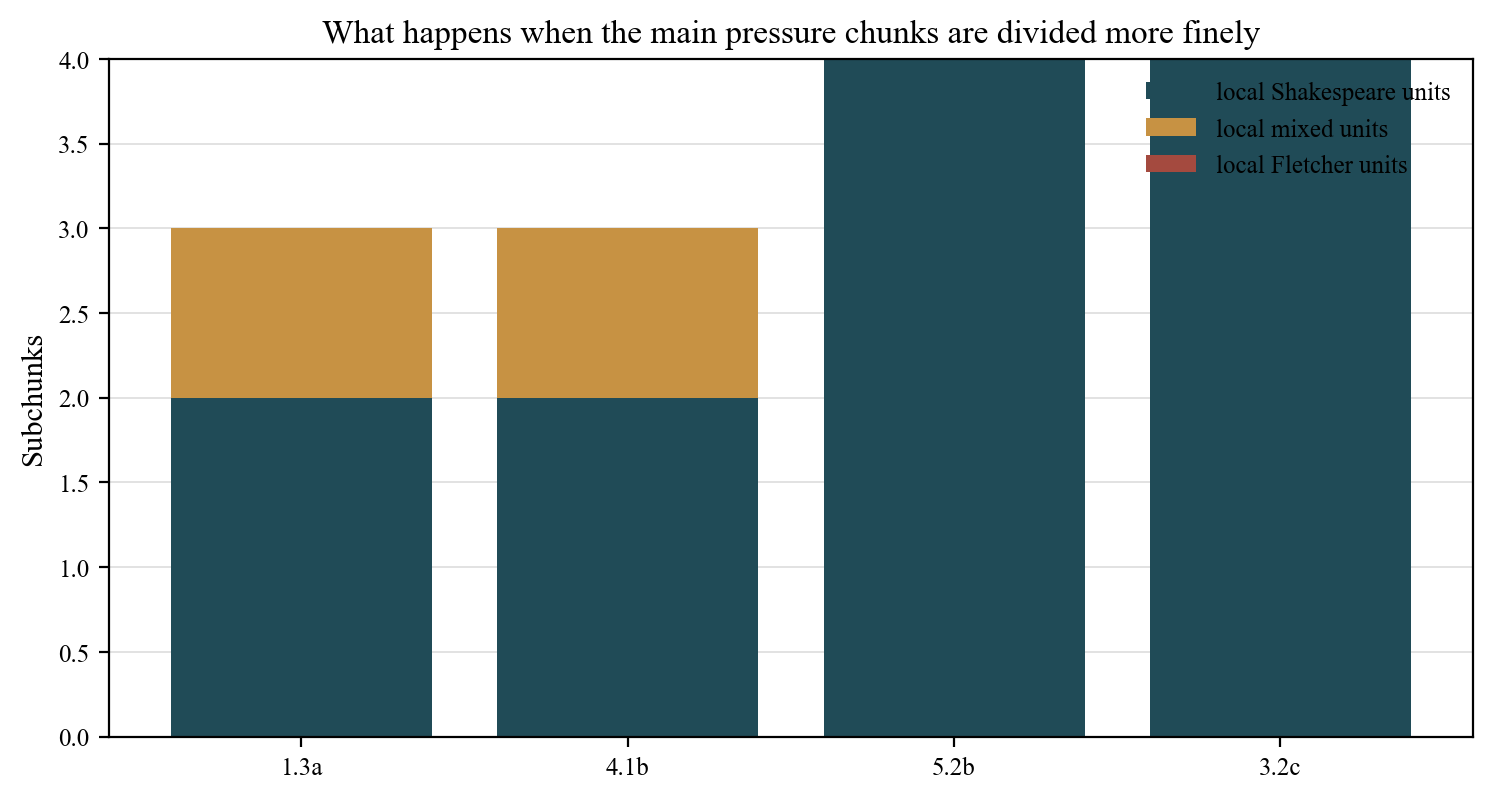
What looked Fletcherian and then weakened
Before local subdivision, several parent chunks looked suspicious. What happened to each under finer resolution is the key story of the project:
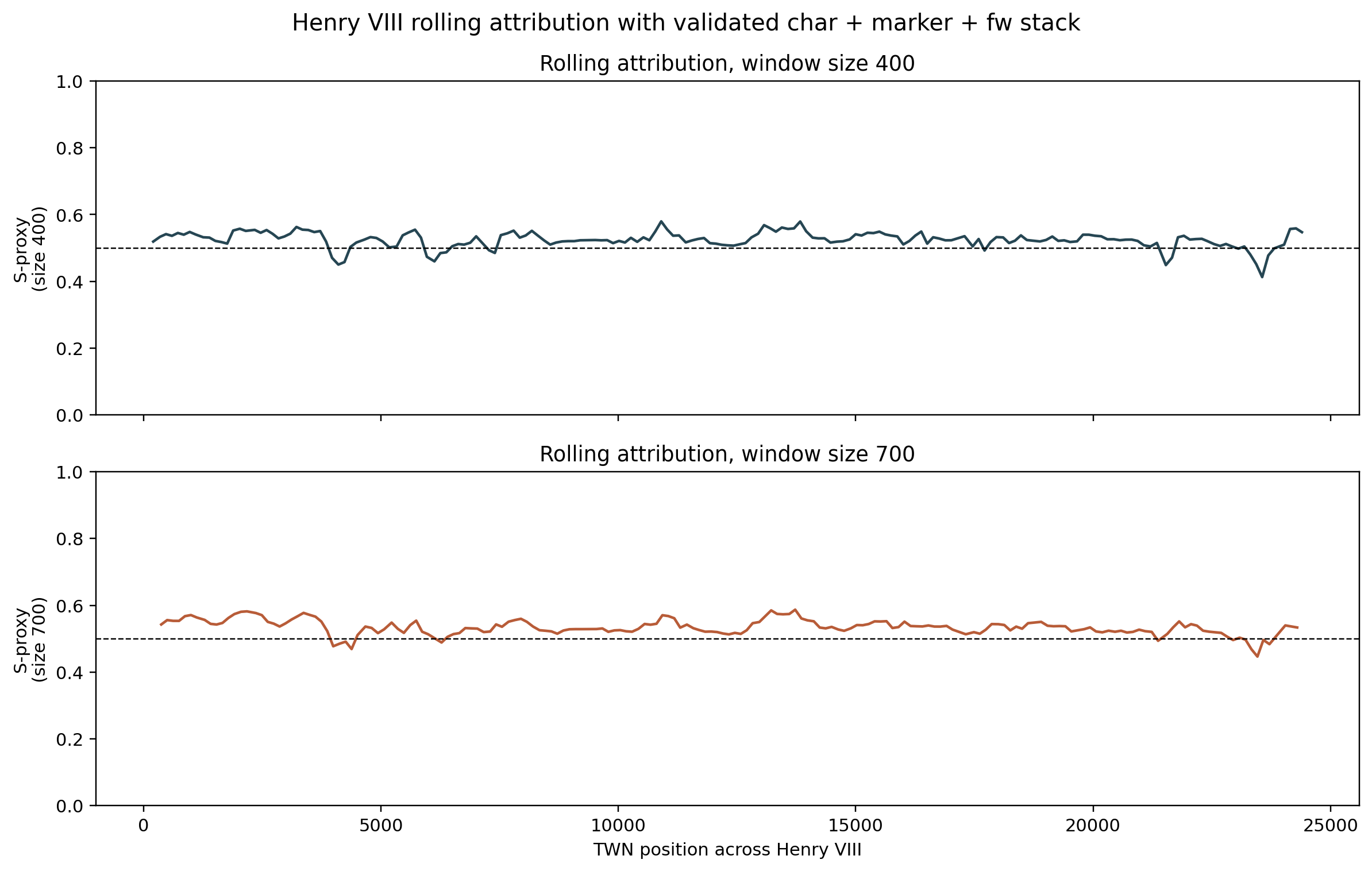
Rolling Attribution: The Continuous View
The rolling attribution pass approaches Henry VIII from the opposite direction from manual chunking: it makes no assumptions about where dramatic units begin and end, and simply asks, window by window, whether each 400- or 700-token stretch is closer to the Shakespeare or Fletcher reference corpus.
The result is striking. The continuous trace is overwhelmingly Mixed, with only a very small number of decisively Fletcher-classified windows:
| Window size | Total windows | Shakespeare | Fletcher | Mixed |
|---|---|---|---|---|
| 400 tokens | 184 | 33 | 3 | 148 |
| 700 tokens | 182 | 32 | 1 | 149 |
The rolling trace does not produce a broad alternating Shakespeare/Fletcher map. The play is not neatly divisible into large Shakespeare blocks and large Fletcher blocks. Instead, most windows sit in the mixed zone, with a small number of strong Shakespeare windows in the Wolsey and trial material, and a handful of Fletcher windows concentrated in 5.3a and, more weakly, 1.3a.
This is the most direct local answer to the Plecháč-style rolling question. The current result is considerably more conservative than Plecháč's. The key methodological differences: the current project's reference corpus is more carefully validated, and the feature stack (trigrams + markers + function words) is different from Plecháč's most-frequent-word plus verse-rhythm combination. Whether this difference reflects a genuine methodological improvement, or reflects the different feature families responding to different aspects of style, is itself an open research question.
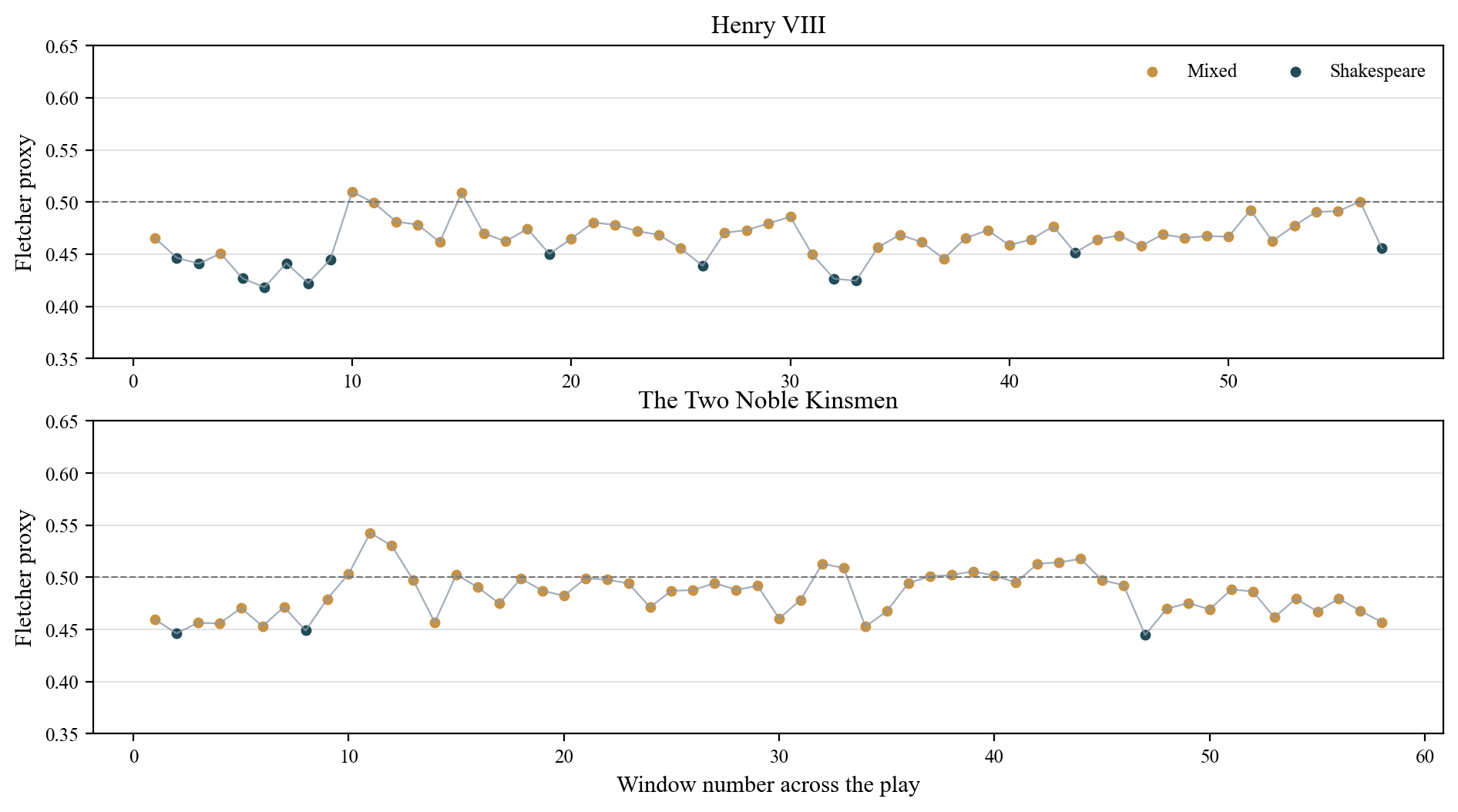
9. The TNK Coarse Benchmark
Under the stricter evidentiary rule, TNK is used only to ask: do Henry VIII and TNK both show coarse mixed internal texture, clearly above the single-author baseline? The answer is yes for both plays — but in different ways.
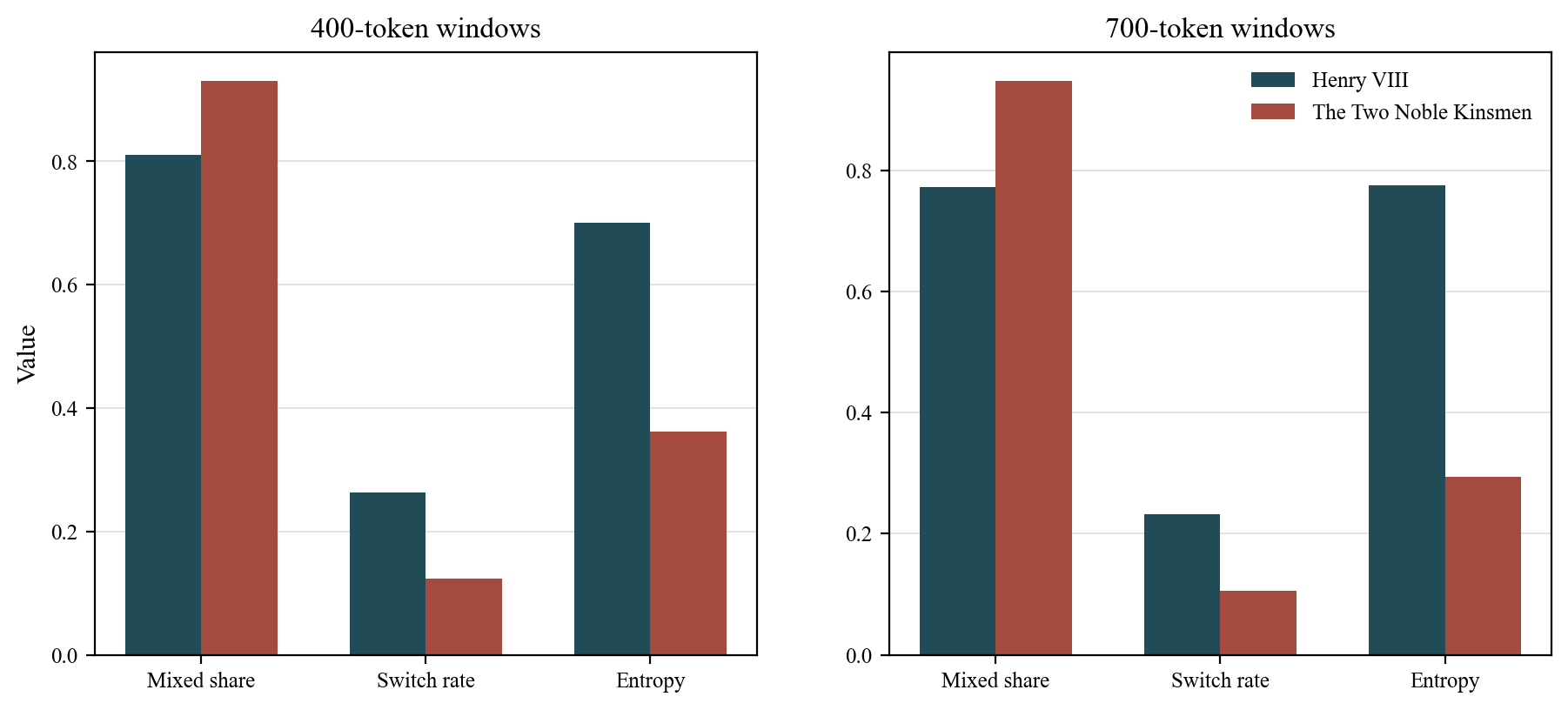
| Play | Window | Windows | Mixed share | Switch rate | Entropy |
|---|---|---|---|---|---|
| Henry VIII | 400 | 58 | 0.810 | 0.263 | 0.701 |
| Henry VIII | 700 | 57 | 0.772 | 0.232 | 0.775 |
| The Two Noble Kinsmen | 400 | 58 | 0.931 | 0.123 | 0.362 |
| The Two Noble Kinsmen | 700 | 58 | 0.948 | 0.105 | 0.294 |
TNK has a higher mixed share — more of its windows sit in the middle zone — but a lower switch rate and lower entropy. This means TNK looks steadily mixed, while Henry VIII looks more volatile: it swings more sharply between Shakespeareward and Fletcherward readings. Both plays are well above the single-author baseline in internal texture complexity.
This difference between the two plays is itself informative. If the method simply flattened all plays into undifferentiated ambiguity, Henry VIII and TNK would look identical. They do not. Henry VIII is more volatile; TNK is more uniformly mixed. That distinction is consistent with Henry VIII having a strong Shakespearean backbone with a smaller number of concentrated Fletcherward pockets, while TNK has more evenly interleaved authorial contributions.
10. CWFP Results
The CWFP pass provides a new kind of evidence because it is based on common content words rather than function words or markers. A chunk that shows Fletcherward pressure in CWFP cannot be dismissed by arguing that the refined stack merely reflects marker frequency or function-word habit.
Summary of CWFP classifications
CWFP does not restore the traditional large Fletcher share. Only one chunk receives a clear Fletcher classification — 5.4b (Cranmer's first prophecy movement), whose nearest CWFP neighbor is Fletcher's Valentinian. But the margin pattern is more informative than the classification count: many chunks that CWFP classifies as Mixed are slightly closer to the Fletcher reference than to Shakespeare, and these subtle margins converge with other methods in consistent ways.
Most Fletcher-leaning by CWFP
| Chunk | Label | CWFP Fletcher margin | Nearest play |
|---|---|---|---|
5.4b | Cranmer's first prophecy | −0.025 | Fletcher / Valentinian |
3.2d | Wolsey after the fall | −0.017 | Fletcher / Valentinian |
3.1b | Cardinals with Katherine | −0.016 | Fletcher / Valentinian |
4.2b | Griffith's defense and Katherine's vision | −0.010 | Fletcher / Valentinian |
4.1b | Coronation procession | −0.010 | Fletcher / The Mad Lover |
2.2b | Wolsey-Campeius divorce management | −0.009 | Fletcher / Valentinian |
5.3a | Porter comic crowd-control | −0.009 | Fletcher / The Woman's Prize |
Most Shakespeare-leaning by CWFP
| Chunk | Label | CWFP Shakespeare margin | Nearest play |
|---|---|---|---|
1.1c | Buckingham arrest and fatal exit | +0.041 | Shakespeare / Measure for Measure |
2.4d | King's conscience narrative | +0.039 | Shakespeare / King Lear |
1.2c | Buckingham matter and surveyor | +0.037 | Shakespeare / Measure for Measure |
2.4c | King's vindication of Wolsey | +0.036 | Shakespeare / Antony and Cleopatra |
3.2a | Noble coalition and exposure | +0.033 | Shakespeare / Measure for Measure |
1.1b | Wolsey grievance and foreign-policy | +0.030 | Shakespeare / Henry V |
CWFP–Marker Crosswalk
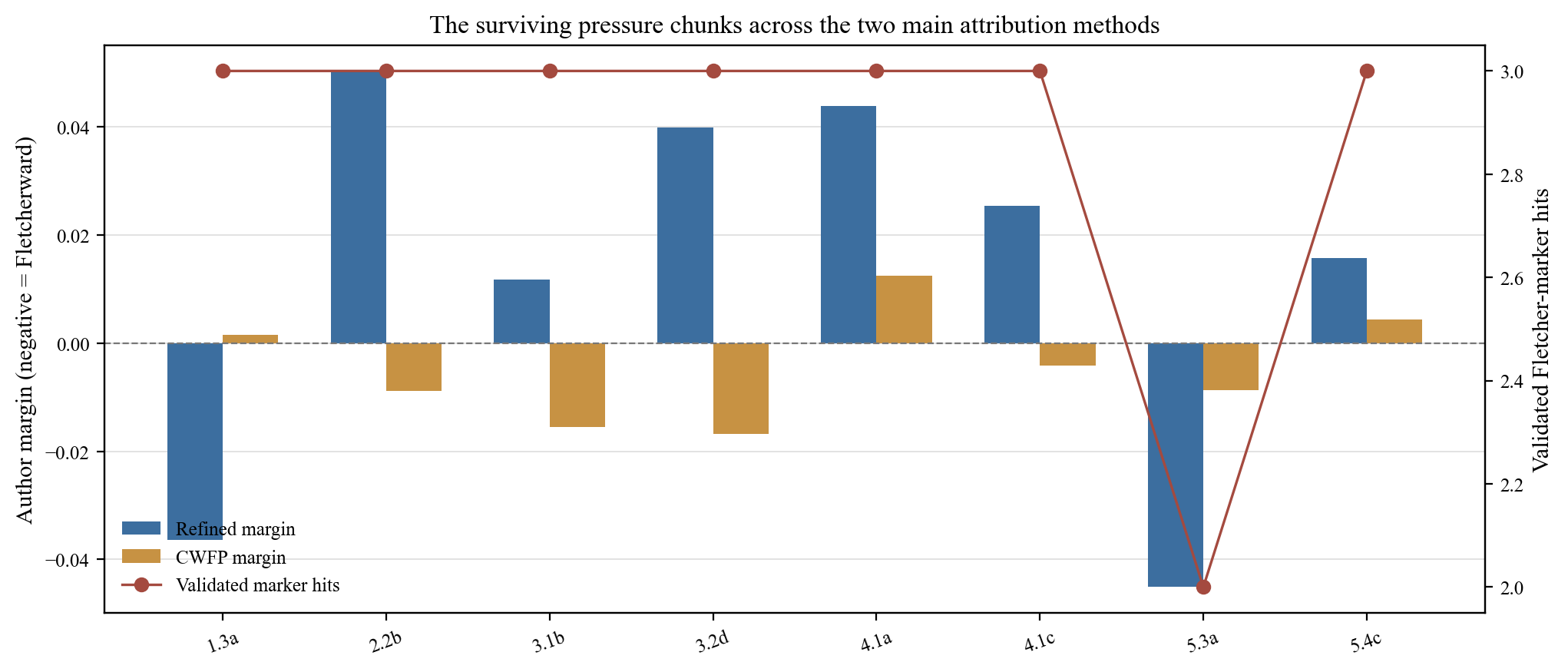
Cross-method convergence is the strongest form of evidence available. The following chunks show both high validated marker hits (≥3) and a Fletcherward CWFP margin:
| Chunk | Label | Marker hits | CWFP nearest | Refined result |
|---|---|---|---|---|
1.3a | Court satire and French fashions | 3 | Fletcher / The Mad Lover | F-like |
2.2b | Wolsey-Campeius divorce management | 3 | Fletcher / Valentinian | Sh-like |
3.1b | Cardinals with Katherine | 3 | Fletcher / Valentinian | Mixed |
3.2d | Wolsey after the fall | 3 | Fletcher / Valentinian | Sh-like |
4.1a | Gentlemanly prelude to coronation | 3 | Fletcher / The Mad Lover | Sh-like |
4.1c | Third Gentleman narrates coronation | 3 | Fletcher / The Mad Lover | Sh-like |
5.4c | Final prophecy and king's answer | 3 | Fletcher / Valentinian | Mixed |
Note that several of these chunks — 2.2b, 3.2d, 4.1a, 4.1c — are classified as Shakespeare-like by the refined stack despite having high marker counts and Fletcherward CWFP neighbors. This is an important interpretive point: it suggests that the marker and content-word signals in these chunks may be picking up dramatic mode (ceremonial narration, counselor banter, public accusation) rather than authorial identity. The genre/mode contamination test was designed precisely to investigate this possibility.
11. The Genre/Mode Contamination Test: Results
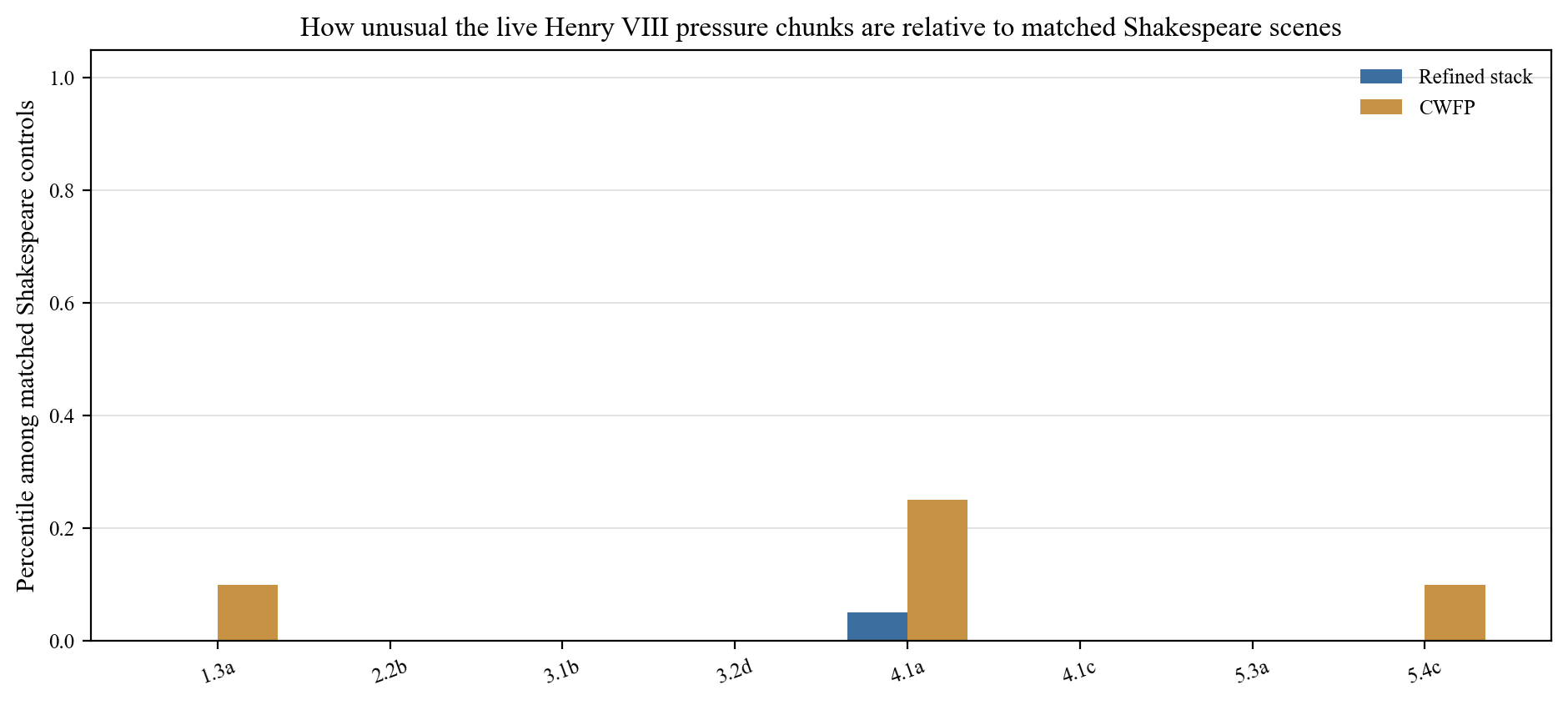
This is the methodological crux of the project. For each surviving pressure chunk, the test found 20 exact-length windows from secure Shakespeare plays with the closest available dramatic geometry (speaker count, turn structure, speaker concentration). Those confirmed-Shakespeare windows were then run through the refined stack and CWFP. If they also drift Fletcherward, the Henry VIII pressure could be dismissed as a mode effect. If they do not, the contamination defense weakens.
| Chunk | Label | Refined target | Matched Sh controls (F/M/S) | Refined percentile | CWFP target | Matched Sh controls (F/M/S) | CWFP percentile |
|---|---|---|---|---|---|---|---|
1.3a | Court satire | F-like | 0 F / 1 M / 19 S | 0.000 | Mixed | 0 F / 9 M / 11 S | 0.100 |
2.2b | Wolsey-Campeius | Sh-like | 0 F / 0 M / 20 S | 0.000 | Mixed | 0 F / 10 M / 10 S | 0.000 |
3.1b | Cardinals with Katherine | Mixed | 0 F / 0 M / 20 S | 0.000 | Mixed | 0 F / 5 M / 15 S | 0.000 |
3.2d | Wolsey after the fall | Sh-like | 0 F / 0 M / 20 S | 0.000 | Mixed | 0 F / 6 M / 14 S | 0.000 |
4.1a | Gentlemanly prelude | Sh-like | 0 F / 1 M / 19 S | 0.050 | Mixed | 0 F / 11 M / 9 S | 0.250 |
4.1c | Third Gentleman narrates | Sh-like | 0 F / 0 M / 20 S | 0.000 | Mixed | 0 F / 8 M / 12 S | 0.000 |
5.3a | Porter crowd-control | F-like | 0 F / 0 M / 20 S | 0.000 | Mixed | 0 F / 12 M / 8 S | 0.000 |
5.4c | Final prophecy | Mixed | 0 F / 3 M / 17 S | 0.000 | Mixed | 0 F / 12 M / 8 S | 0.100 |
The percentile column is the key number. A percentile of 0.000 means the Henry VIII chunk is more Fletcherward than every single one of the 20 matched Shakespeare controls. Most of the live pressure chunks achieve this. This is a strong result: it means the contamination objection cannot explain away the pressure in these specific locations.
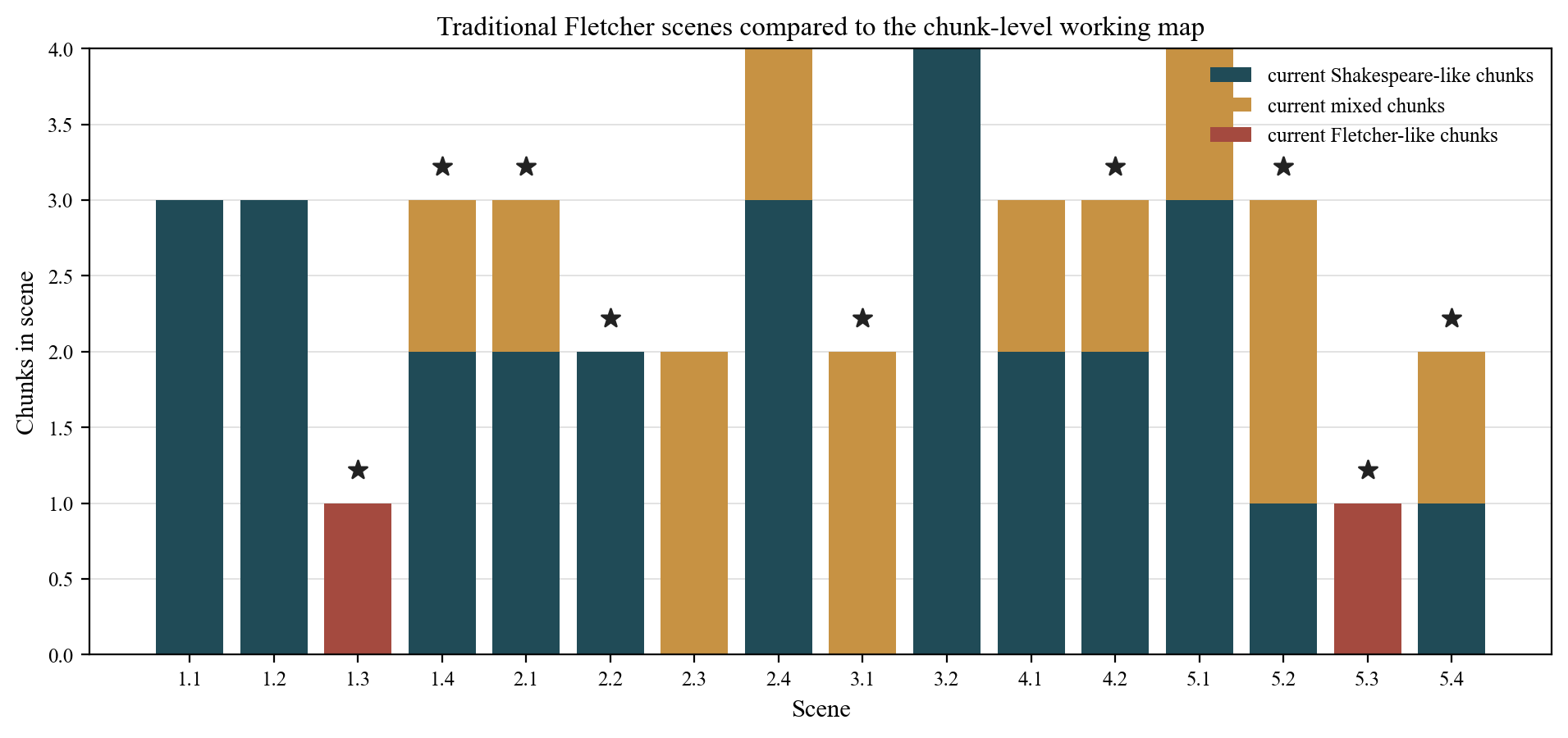
12. Comparing the Current Map to the Traditional Scene Partition
The following table shows each of the sixteen scenes in Henry VIII, indicating whether traditional scholarship assigned it to Fletcher, how many validated marker hits the current analysis found, and how the current chunk-level analysis distributes the scene's local units.
| Scene | Traditional Fletcher scene? | Validated marker hits | Current Sh-like chunks | Current Mixed chunks | Current F-like chunks |
|---|---|---|---|---|---|
| 1.1 | No | 1 | 3 | — | — |
| 1.2 | No | 1 | 3 | — | — |
| 1.3 | Yes (Spedding) | 3 | — | — | 1 |
| 1.4 | Yes (Spedding) | 2 | 2 | 1 | — |
| 2.1 | Yes (Spedding) | 3 | 2 | 1 | — |
| 2.2 | Yes (Spedding) | 2 | 2 | — | — |
| 2.3 | No | 1 | — | 2 | — |
| 2.4 | No | 1 | 3 | 1 | — |
| 3.1 | Yes (Spedding) | 3 | — | 2 | — |
| 3.2 | No (partly in some traditions) | — | 4 | — | — |
| 4.1 | No (Spedding had it Sh) | 3 | 2 | 1 | — |
| 4.2 | Yes (Spedding) | 1 | 2 | 1 | — |
| 5.1 | No | — | 3 | 1 | — |
| 5.2 | Yes (some traditions) | 1 | 1 | 2 | — |
| 5.3 | Yes (Spedding) | 2 | — | — | 1 |
| 5.4 | Yes (Spedding) | 1 | 1 | 1 | — |
The most striking pattern: among the nine scenes that Spedding assigned to Fletcher, the current chunk-level analysis finds only two scenes that contain any F-like chunks (1.3 and 5.3). The other seven scenes that Spedding called Fletcher territory contain chunks that resolve as Shakespearean or Mixed under the current analysis. This does not mean Spedding was entirely wrong — his pressure instincts were often correct at the scene level. It means the Fletcher signal within those scenes is often local rather than scene-wide.
13. Conclusions
The findings can be stated in a way that is both cautious and affirmative. They do not require choosing between "Spedding was right" and "the play is all Shakespeare." A more specific and better-supported picture is available.
What would change the picture
The following findings would substantially revise the current conclusions:
- A larger, better-balanced Fletcher reference corpus (currently only 6 plays) that improves Fletcher recovery in validation — this would allow stronger positive Fletcher claims
- A validated spelling investigation on the diplomatic Folger text that shows systematic colloquial contraction patterns aligning with the pressure chunks — this would strengthen the marker evidence
- A Plecháč-style replication that uses the same feature stack as the current project but finds broader Fletcher blocks — this would indicate the difference is in the reference corpus rather than the features
- Newly discovered documentary evidence linking Fletcher to the play — this would remove the inference problem entirely, though it would not settle the internal map
Appendix: Complete Chunk-by-Chunk Method Ledger
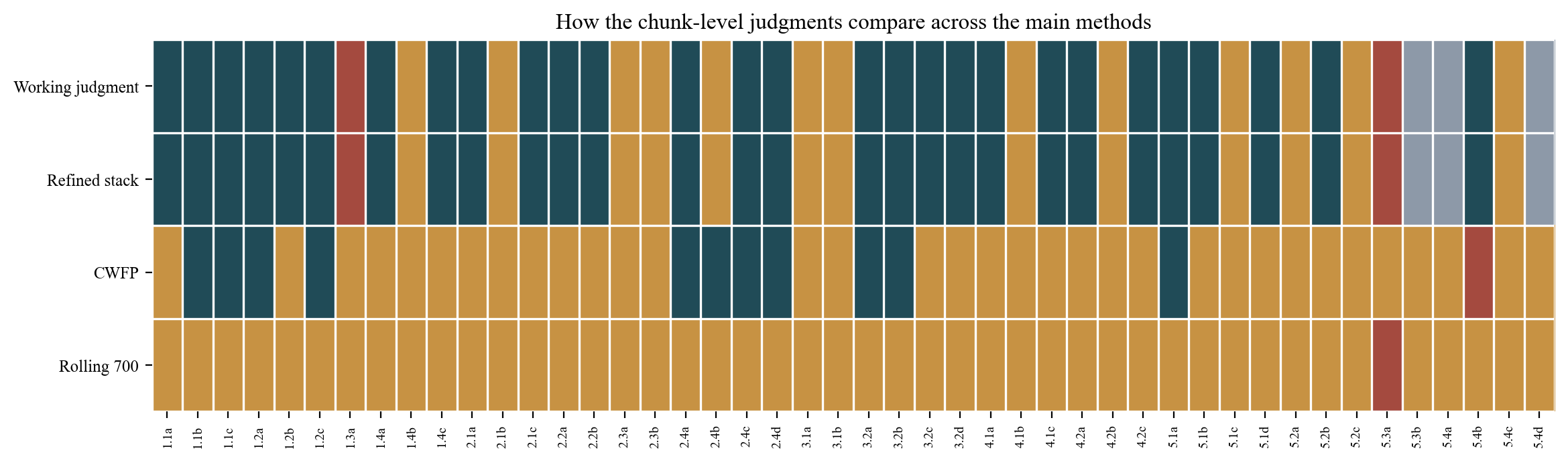
The following table gives all 46 chunks with their scene assignment, token count, short label, and judgments from the four main analysis layers: the refined stack, CWFP, rolling attribution at 400 and 700 tokens, validated marker hit count, and the working judgment that synthesizes across methods.
| Chunk | Scene | Tokens | Label | Refined | CWFP | Roll 400 | Roll 700 | Markers | Judgment |
|---|---|---|---|---|---|---|---|---|---|
1.1a | 1.1 | 681 | Field-of-Cloth spectacle | Sh | Mix | Mix | Mix | 1 | Sh-like |
1.1b | 1.1 | 1159 | Wolsey grievance and corruption | Sh | Sh | Mix | Mix | 3 | Sh-like |
1.1c | 1.1 | 237 | Buckingham arrest | Sh | Sh | Sh | Mix | 2 | Sh-like |
1.2a | 1.2 | 423 | Royal opening and grievance | Sh | Sh | Mix | Mix | 1 | Sh-like |
1.2b | 1.2 | 437 | Taxation debate and revocation | Sh | Mix | Mix | Mix | 2 | Sh-like |
1.2c | 1.2 | 871 | Buckingham matter and surveyor | Sh | Sh | Mix | Mix | 2 | Sh-like |
1.3a | 1.3 | 575 | Court satire, French fashions | Fl | Mix | Fl | Mix | 3 | F-like |
1.4a | 1.4 | 293 | Banquet wit and erotic banter | Sh | Mix | Mix | Mix | 3 | Sh-like |
1.4b | 1.4 | 228 | Wolsey's feast under interruption | Mix | Mix | Mix | Mix | 2 | Mixed |
1.4c | 1.4 | 373 | Masque recognition, Anne singled out | Sh | Mix | Mix | Mix | 3 | Sh-like |
2.1a | 2.1 | 441 | Gentlemen on Buckingham's trial | Sh | Mix | Mix | Mix | 3 | Sh-like |
2.1b | 2.1 | 708 | Buckingham's public valediction | Mix | Mix | Mix | Mix | 2 | Mixed |
2.1c | 2.1 | 262 | Aftermath and divorce rumor | Sh | Mix | Mix | Mix | 2 | Sh-like |
2.2a | 2.2 | 674 | Anti-Wolsey counsel | Sh | Mix | Mix | Mix | 3 | Sh-like |
2.2b | 2.2 | 488 | Wolsey-Campeius divorce management | Sh | Mix | Mix | Mix | 3 | Sh-like |
2.3a | 2.3 | 412 | Anne's pity, anti-eminence talk | Mix | Mix | Mix | Mix | 2 | Mixed |
2.3b | 2.3 | 475 | Elevation of Anne | Mix | Mix | Mix | Mix | 2 | Mixed |
2.4a | 2.4 | 438 | Ceremonial opening, Katherine's plea | Sh | Sh | Mix | Mix | 1 | Sh-like |
2.4b | 2.4 | 601 | Wolsey-Campeius answer, Katherine's refusal | Mix | Sh | Mix | Mix | — | Mixed |
2.4c | 2.4 | 28 | King's vindication of Katherine | Sh | Sh | Mix | Mix | 2 | Sh-like |
2.4d | 2.4 | 595 | King's conscience narrative | Sh | Sh | Mix | Mix | 2 | Sh-like |
3.1a | 3.1 | 165 | Katherine's melancholy and reception | Mix | Mix | Mix | Mix | 2 | Mixed |
3.1b | 3.1 | 1347 | Cardinals with Katherine | Mix | Mix | Mix | Mix | 3 | Mixed |
3.2a | 3.2 | 607 | Noble coalition, anti-Wolsey exposure | Sh | Sh | Mix | Mix | — | Sh-like |
3.2b | 3.2 | 679 | Packet exchange, Wolsey's alarm | Sh | Sh | Mix | Mix | 2 | Sh-like |
3.2c | 3.2 | 123 | Wolsey confronted and stripped | Sh | Mix | Mix | Mix | 3 | Sh-like |
3.2d | 3.2 | 935 | Wolsey after the fall | Sh | Mix | Mix | Mix | 3 | Sh-like |
4.1a | 4.1 | 295 | Gentlemanly prelude to coronation | Sh | Mix | Mix | Mix | 3 | Sh-like |
4.1b | 4.1 | 157 | Coronation procession | Mix | Mix | Mix | Mix | 2 | Mixed |
4.1c | 4.1 | 53 | Third Gentleman narrates coronation | Sh | Mix | Mix | Mix | 3 | Sh-like |
4.2a | 4.2 | 358 | Katherine judges Wolsey | Sh | Mix | Mix | Mix | 2 | Sh-like |
4.2b | 4.2 | 277 | Griffith's defense, Katherine's vision | Mix | Mix | Mix | Mix | 1 | Mixed |
4.2c | 4.2 | 745 | Capuchius, Katherine's final petitions | Sh | Mix | Mix | Mix | 3 | Sh-like |
5.1a | 5.1 | 472 | Gardiner and Lovell on Cranmer | Sh | Sh | Mix | Mix | 2 | Sh-like |
5.1b | 5.1 | 223 | King, Suffolk, queen's labor | Sh | Mix | Mix | Mix | — | Sh-like |
5.1c | 5.1 | 584 | King and Cranmer in private | Mix | Mix | Mix | Mix | 2 | Mixed |
5.1d | 5.1 | 16 | Birth report, Old Lady comic close | Sh | Mix | Mix | Mix | 2 | Sh-like |
5.2a | 5.2 | 289 | Cranmer waiting, king observes | Mix | Mix | Mix | Mix | 2 | Mixed |
5.2b | 5.2 | 787 | Council attack on Cranmer | Sh | Mix | Mix | Mix | 3 | Sh-like |
5.2c | 5.2 | 735 | Ring and royal restoration | Mix | Mix | Mix | Mix | 2 | Mixed |
5.3a | 5.3 | 592 | Porter comic crowd-control | Fl | Mix | Fl | Fl | 2 | F-like |
5.3b | 5.3 | 138 | Chamberlain restores order | — | Mix | Mix | Mix | 1 | — |
5.4a | 5.4 | 67 | Procession naming, opening blessing | — | Mix | Mix | Mix | — | — |
5.4b | 5.4 | 359 | Cranmer's first prophecy | Sh | Fl | Mix | Mix | 1 | Sh-like |
5.4c | 5.4 | 182 | Final prophecy and king's answer | Mix | Mix | Mix | Mix | 3 | Mixed |
5.4d | 5.4 | 123 | Epilogue | — | Mix | Mix | Mix | 2 | — |
Works Cited and Comparison Points
- Spedding, James. "Who Wrote Shakespeare's Henry VIII?" Gentleman's Magazine (1850). Princeton archive.
- Hoy, Cyrus. "The Shares of Fletcher and His Collaborators in the Beaumont and Fletcher Canon." Studies in Bibliography 8–15 (1956–1962).
- Hope, Jonathan. The Authorship of Shakespeare's Plays: A Socio-linguistic Study. Cambridge: Cambridge UP, 1994. Cambridge chapter.
- Vickers, Brian. Shakespeare, Co-Author: A Historical Study of Five Collaborative Plays. Oxford: OUP, 2002. OUP.
- Craig, Hugh and Arthur F. Kinney. Shakespeare, Computers, and the Mystery of Authorship. Cambridge: Cambridge UP, 2009.
- Plecháč, Petr. "Relative contributions of Shakespeare and Fletcher in Henry VIII: An Analysis Based on Most Frequent Words and Most Frequent Rhythmic Patterns." Digital Scholarship in the Humanities 36.2 (2021): 430–438. arXiv preprint · Published version · Replication data.
- Sharpe, Will, ed. King Henry VIII; or All is True. New Oxford Shakespeare. Oxford: OUP, 2016.
- Sharpe, Will. Shakespeare & Collaborative Writing. Oxford Shakespeare Topics. Oxford: OUP, 2023.
- Margeson, John, intro. Henry VIII. Cambridge: Cambridge UP. Cambridge appendix.
- Folger Shakespeare Library. Henry VIII Appendix on Authorship. Folger.
- Stanford Global Shakespeare Encyclopedia, "Henry VIII" entry. Stanford.
Henry VIII Authorship Project · March 2026 · Codex research workspace
Database: early_modern_plays.db · 527 plays · Target: play ID 502 · Chunks: 46